FactorizedHMR: A Hybrid Framework for Video Human Mesh Recovery
Human Mesh Recovery (HMR) is fundamentally ambiguous: under occlusion or weak depth cues, multiple 3D bodies can explain the same image evidence. Building on this observation, we propose FactorizedHMR, a two-stage framework that treats these two regimes differently.
Abstract
Human Mesh Recovery (HMR) is fundamentally ambiguous: under occlusion or weak depth cues, multiple 3D bodies can explain the same image evidence. This ambiguity is not uniform across the body, as torso pose and root structure are often relatively well constrained, whereas distal articulations such as the arms and legs are more uncertain. Building on this observation, we propose FactorizedHMR, a two-stage framework that treats these two regimes differently. A deterministic regression module first recovers a stable torso-root anchor, and a probabilistic flow-matching module then completes the remaining non-torso articulation. To make this completion reliable, we combine a composite target representation with geometry-aware supervision and feature-aware classifier-free guidance, preserving the torso-root anchor while improving single-reference recovery of ambiguity-prone articulation. We also introduce a synthetic data pipeline that provides the paired image-camera-motion supervision under diverse viewpoints. Across camera-space and world-space benchmarks, FactorizedHMR remains competitive with strong baselines, with the clearest gains in occlusion-heavy recovery and drift-sensitive world-space metrics.
Motivation
Human Mesh Recovery (HMR) reconstructs 3D human pose, shape, and motion from visual observations. Yet video HMR remains difficult under partial observation, especially with occlusion, truncation, and depth ambiguity, where multiple plausible 3D bodies can explain the same image evidence.
Deterministic methods are efficient, but under ambiguity they often regress toward an average solution. Probabilistic methods are more expressive, but modeling the full state stochastically can waste capacity on well-constrained torso, root, and camera variables that are often better handled deterministically.
This motivates our central claim: HMR benefits from uncertainty-aware completion, in which stable variables are estimated deterministically while ambiguity-prone variables are refined probabilistically.
Contributions
- We propose FactorizedHMR, a hybrid video HMR framework that decouples stable torso-root estimation from ambiguity-prone motion completion.
- We formulate selective probabilistic HMR as masked conditional flow matching, keeping anchor variables fixed while generating only non-torso and world-motion variables.
- We introduce geometry-aware completion objectives that combine composite rotation-joint targets, representation-aware noising, joint-bone consistency, projection loss, and feature-aware CFG.
- We develop a camera-aware synthetic training pipeline and demonstrate competitive overall performance, with the strongest gains under severe occlusion.




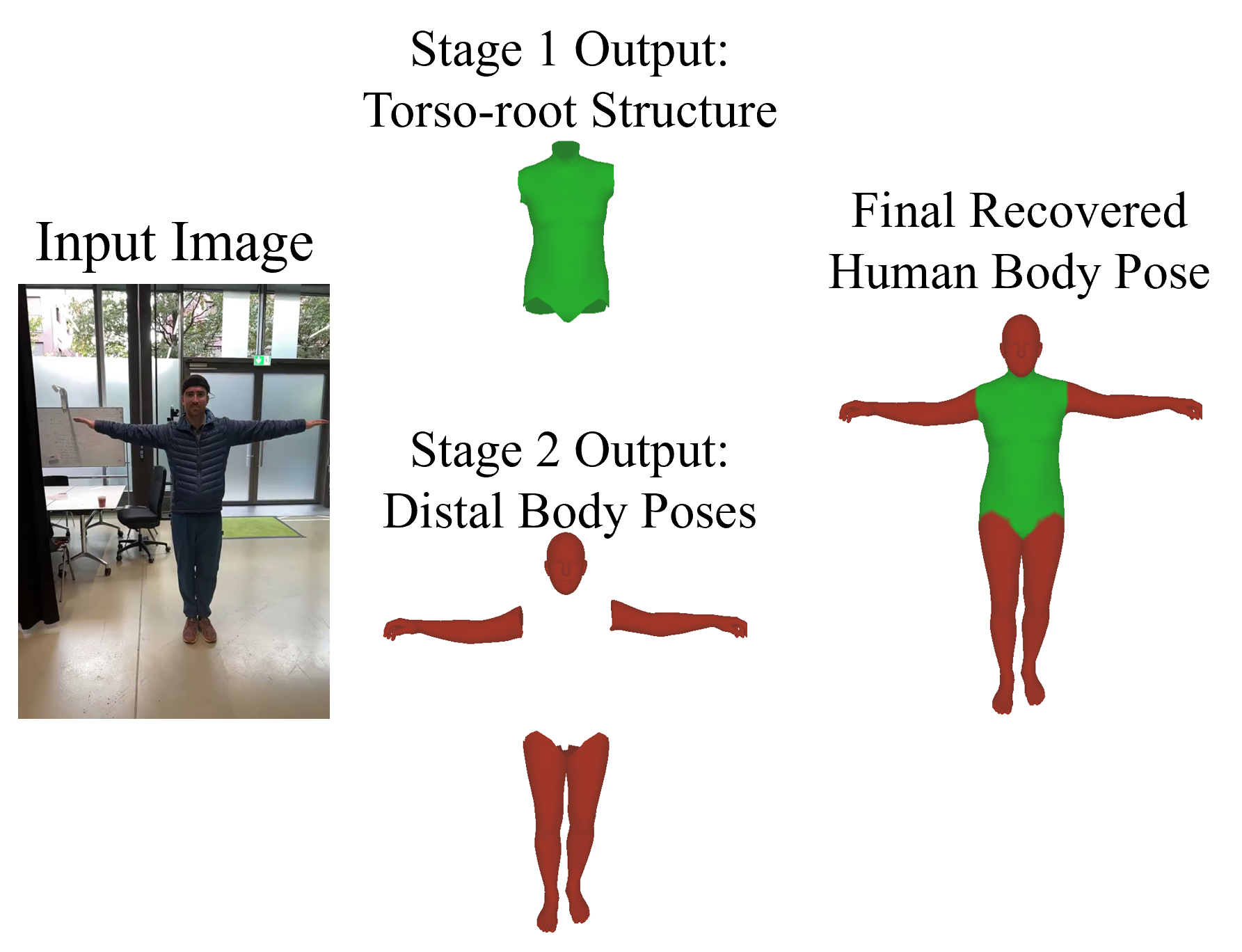
Method
Given an input video, our goal is to recover temporally consistent human motion in both camera space and world space. Torso pose, body shape, and camera-space root motion are usually well constrained and form a structural anchor, while non-torso articulation and world motion are more ambiguous because they are more sensitive to occlusion, truncation, and camera-body disentanglement.
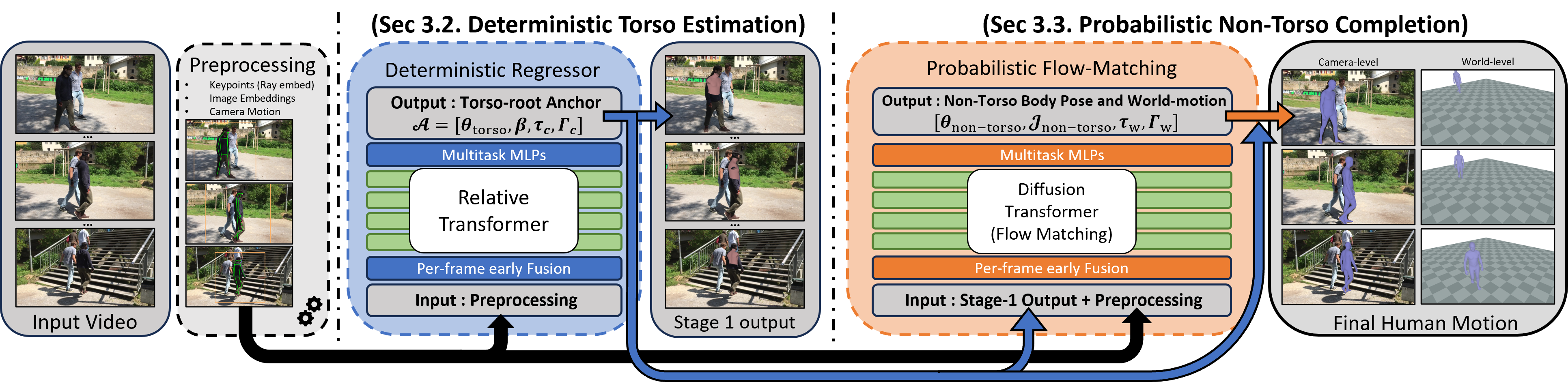
Stage 1: Deterministic Structural Estimation
Stage 1 uses a deterministic transformer with rotary position embeddings, motivated by GVHMR, to estimate the structural anchor. It predicts only torso pose, body shape, and camera-space trajectory variables, deferring the more ambiguous world-motion components to Stage 2.
Inputs include bounding-box features, 2D keypoint observations, image features, and relative camera-motion features. Keypoints are converted to camera-ray directions with the intrinsics, embedded with sinusoidal encodings, projected by per-modality MLPs, and summed into per-frame tokens for the relative transformer.
Stage 2: Non-Torso Articulation and World Completion via Masked Flow Matching
Stage 2 augments local rotations with 3D camera-space joint positions, since rotations alone do not directly expose resulting limb geometry. Variables copied from Stage 1 are fixed by the mask, while Stage 2 generates the non-torso and world-motion subset; the rotation branch defines the final body and the joint-position branch provides auxiliary geometric supervision.
We split the latent into known coordinates from the structural anchor and unknown coordinates for ambiguous non-torso and world-motion variables. At inference, only the generated coordinates start from Gaussian noise, and an ODE sampler re-imposes the known coordinates after each update to produce conditional completion around a fixed structural anchor.
Anchor Conditioning and CFG
Stage 2 shares the visual and camera conditions used by Stage 1 and also receives a compact torso-pose condition from the Stage 1 anchor. We apply classifier-free guidance by dropping observation-heavy conditions during training while keeping the structural-anchor conditions, strengthening observation-conditioned completion without discarding the anchor.
Geometry-Aware Training
In addition to the generative objective, we use geometry-aware losses similar to GVHMR. For Stage 2, these supervise pose, joints, root motion, projected 2D joints and vertices, camera-frame translation, and recovered world translation. We also add joint-bone consistency and a direct projection loss for ambiguous non-torso joints to keep the completed motion consistent with SMPL-X geometry, image evidence, and camera/world trajectory constraints.
Synthetic Dataset Generation Pipeline
Motion-only corpora such as AMASS contain rich human dynamics, but they do not provide paired realistic videos and are therefore insufficient for training models for recovering human motion from imagery. Real videos offer much richer appearance variation, but their annotations are often noisy or incomplete. To address this, we construct a synthetic pipeline that preserves exact motion-capture supervision while using Uni3C as a video synthesis engine, which unifies camera and human-motion control from a single-view image across broader visual domains.
Given a motion sequence and its SMPL-X parameters, we sample a camera trajectory with known camera parameters. We render geometric control signals, including SMPL-X body renderings, hand renderings, masks, and an OpenPose-style first-frame pose. The pose rendering is used to synthesize a reference image with identity and scene prompts using depth-conditioned FLUX.1. We then estimate monocular metric depth for the reference image using Depth Pro and unproject it into a scene point cloud, which serves as the environment coordinate system. The SMPL-X motion and scene point cloud are rendered under the same target camera trajectory, producing aligned human-motion and camera-control conditions for Uni3C. The final RGB video is then generated by Uni3C from the reference image, the rendered point-cloud trajectory, and the rendered human motion.


Results
Both stages use 12-layer transformers with rotary position embeddings, 8 attention heads, and hidden size 512. We train on AMASS, BEDLAM, H36M, and 3DPW, plus Uni3C-based synthetic sequences for additional camera-aware supervision.
We report camera-space metrics on 3DPW, RICH, and EMDB-1; world-space metrics on RICH and EMDB-2; and occlusion-focused results on 3DPW-XOCC.
Camera-Space Motion Recovery
Our method remains highly competitive on standard camera-space benchmarks. MPJPE improves consistently across datasets, while PA-MPJPE and PVE remain broadly competitive, indicating that the factorization improves ambiguous articulation without sacrificing torso stability.
| Models | 3DPW | RICH | EMDB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PA-MPJPE ↓ | MPJPE ↓ | PVE ↓ | PA-MPJPE ↓ | MPJPE ↓ | PVE ↓ | PA-MPJPE ↓ | MPJPE ↓ | PVE ↓ | |
| Per-frame | |||||||||
| CLIFF* | 43.0 | 69.0 | 81.2 | 56.6 | 102.6 | 115.0 | 68.1 | 103.3 | 128.0 |
| HybrIK* | 41.8 | 71.6 | 82.3 | 56.4 | 96.8 | 110.4 | 65.6 | 103.0 | 122.2 |
| HMR2.0 | 44.4 | 69.8 | 82.2 | 48.1 | 96.0 | 110.9 | 60.6 | 98.0 | 120.3 |
| ReFit* | 40.5 | 65.3 | 75.1 | 47.9 | 80.7 | 92.9 | 58.6 | 88.0 | 104.5 |
| Temporal | |||||||||
| VIBE* | 51.9 | 82.9 | 98.4 | 68.4 | 120.5 | 140.2 | 81.4 | 125.9 | 146.8 |
| TRACE* | 50.9 | 79.1 | 95.4 | -- | -- | -- | 70.9 | 109.9 | 127.4 |
| SLAHMR | 55.9 | -- | -- | 52.5 | -- | -- | 69.5 | 93.5 | 110.7 |
| PACE | -- | -- | -- | 49.3 | -- | -- | -- | -- | -- |
| WHAM* | 35.9 | 57.8 | 68.7 | 44.3 | 80.0 | 91.2 | 50.4 | 79.7 | 94.4 |
| GVHMR* | 37.1 | 56.9 | 68.8 | 39.5 | 66.0 | 74.4 | 44.6 | 74.0 | 86.0 |
| TRAM* | 35.6 | 59.3 | 69.6 | -- | -- | -- | 45.7 | 74.4 | 86.6 |
| GENMO* | 42.9 | 62.3 | 82.8 | -- | -- | -- | 47.6 | 81.2 | 94.6 |
| Ours* | 36.9 | 56.2 | 68.3 | 39.1 | 65.8 | 74.5 | 45.7 | 73.6 | 86.5 |
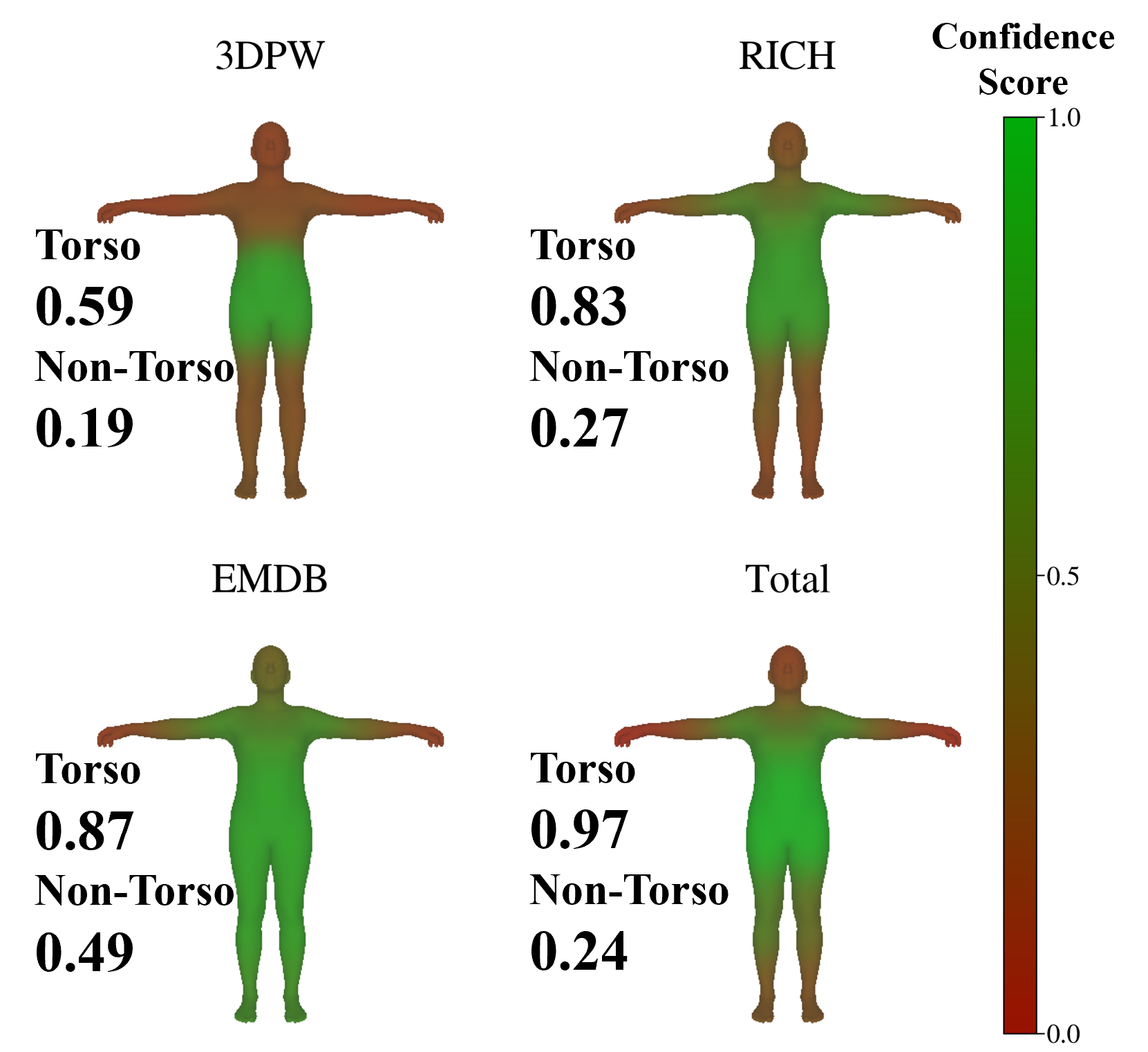
Regional Breakdown
The torso/non-torso split highlights the intended division of labor: Stage 1 improves the torso subset over GVHMR, while Stage 2 achieves the best MPJPE on the non-torso subset across all three datasets.
Torso Setup
| Models | 3DPW | RICH | EMDB | |||
|---|---|---|---|---|---|---|
| PA-MPJPE ↓ | MPJPE ↓ | PA-MPJPE ↓ | MPJPE ↓ | PA-MPJPE ↓ | MPJPE ↓ | |
| GVHMR | 5.96 | 27.31 | 9.03 | 36.79 | 14.96 | 51.56 |
| Ours | 5.72 | 27.21 | 9.00 | 35.82 | 14.26 | 50.03 |
Non-Torso Setup
| Models | 3DPW | RICH | EMDB | |||
|---|---|---|---|---|---|---|
| PA-MPJPE ↓ | MPJPE ↓ | PA-MPJPE ↓ | MPJPE ↓ | PA-MPJPE ↓ | MPJPE ↓ | |
| GVHMR | 39.5 | 64.9 | 45.6 | 80.7 | 51.6 | 85.4 |
| Ours | 39.6 | 64.7 | 45.4 | 79.6 | 53.0 | 84.6 |
torso region predicted by Stage 1. The right table reports the non-torso region refined by Stage 2.
World-Space Motion Recovery and Occlusion-Specific Benchmark
In world space, the clearest gain appears on drift-sensitive W-MPJPE, suggesting better long-horizon coherence. On 3DPW-XOCC, our method achieves the best performance on all reported metrics, showing the largest benefits under severe occlusion.
| Models | EMDB | RICH | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| WA-MPJPE ↓ | W-MPJPE ↓ | Root translation ↓ | Jitter ↓ | Foot-sliding ↓ | WA-MPJPE ↓ | W-MPJPE ↓ | Root translation ↓ | Jitter ↓ | Foot-sliding ↓ | |
| TRACE | 529.0 | 1702.3 | 17.7 | 2987.6 | 370.7 | 238.1 | 925.4 | 610.4 | 1578.6 | 230.7 |
| GLAMR | 280.8 | 726.6 | 11.4 | 46.3 | 20.7 | 129.4 | 236.2 | 3.8 | 49.7 | 18.1 |
| SLAHMR | 326.9 | 776.1 | 10.2 | 31.3 | 14.5 | 98.1 | 186.4 | 28.9 | 34.3 | 5.1 |
| WHAM | 135.6 | 354.8 | 6.0 | 22.5 | 4.4 | 109.9 | 184.6 | 4.1 | 19.7 | 3.3 |
| GVHMR | 111.0 | 276.5 | 2.0 | 16.7 | 3.5 | 78.8 | 126.3 | 2.4 | 12.8 | 3.0 |
| TRAM | 76.4 | 222.4 | 1.4 | 18.1 | 11.0 | -- | -- | -- | -- | -- |
| GENMO | 65.1 | 210.9 | 1.0 | 9.58 | 8.3 | 80.7 | 127.2 | 2.6 | 8.6 | 2.7 |
| Ours | 70.5 | 192.5 | 1.5 | 17.7 | 9.3 | 86.6 | 123.3 | 2.5 | 17.7 | 8.6 |
| Methods | MPJPE ↓ | PA-MPJPE ↓ | PVE ↓ |
|---|---|---|---|
| HybrIK | 148.3 | 98.7 | 164.5 |
| PARE | 114.2 | 67.7 | 133.0 |
| PARE + VIBE | 97.3 | 60.2 | 114.9 |
| NIKI (frame-based) | 110.7 | 60.5 | 128.6 |
| NIKI (temporal) | 88.9 | 52.1 | 98.0 |
| GENMO | 76.2 | 48.4 | 94.2 |
| Ours | 66.3 | 45.1 | 81.2 |
Ablation Studies
Adding Stage 2 yields the largest improvement, showing that the torso-root anchor alone is not enough for full-body recovery. Composite representation, geometry-aware losses, CFG scaling, and synthetic data each provide further gains.
| Variant | PA-MPJPE ↓ | MPJPE ↓ | PVE ↓ |
|---|---|---|---|
| Stage 1 Model | 65.0 | 77.0 | 122.4 |
| + Stage 2 Model | 39.9 | 60.3 | 73.3 |
| + Composite Representation | 39.4 | 59.2 | 71.8 |
| + Geometry-aware losses | 37.2 | 57.2 | 69.2 |
| + CFG scaling | 37.1 | 56.5 | 68.5 |
| + synthetic dataset | 36.9 | 56.2 | 68.3 |




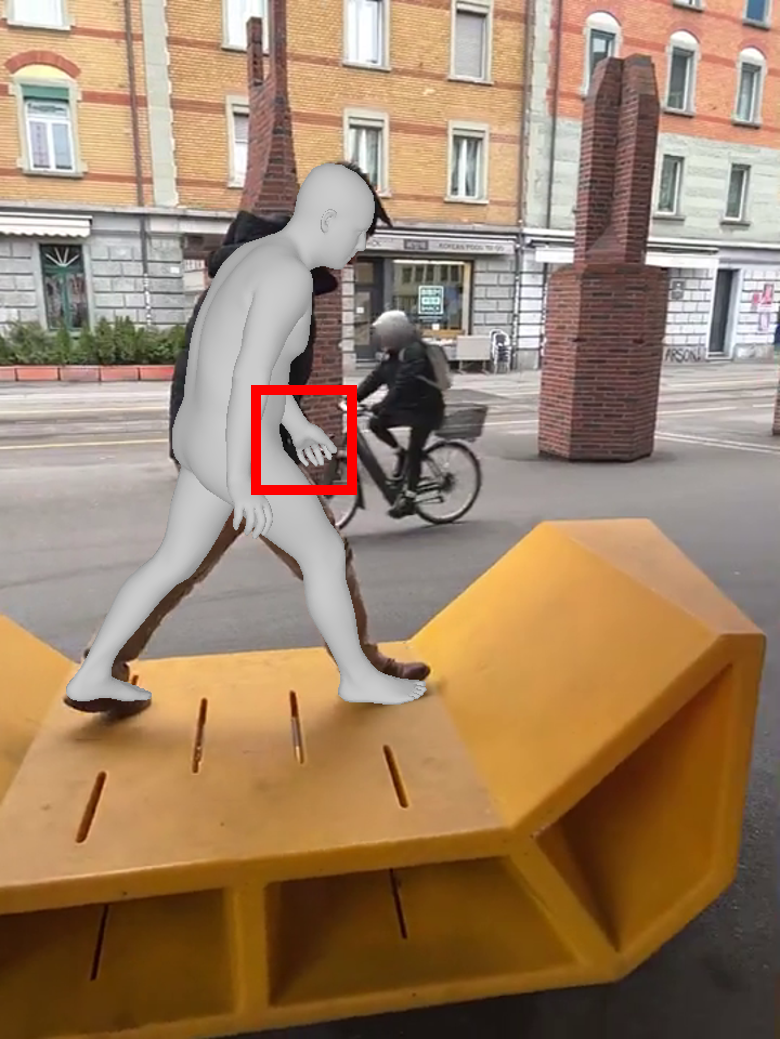
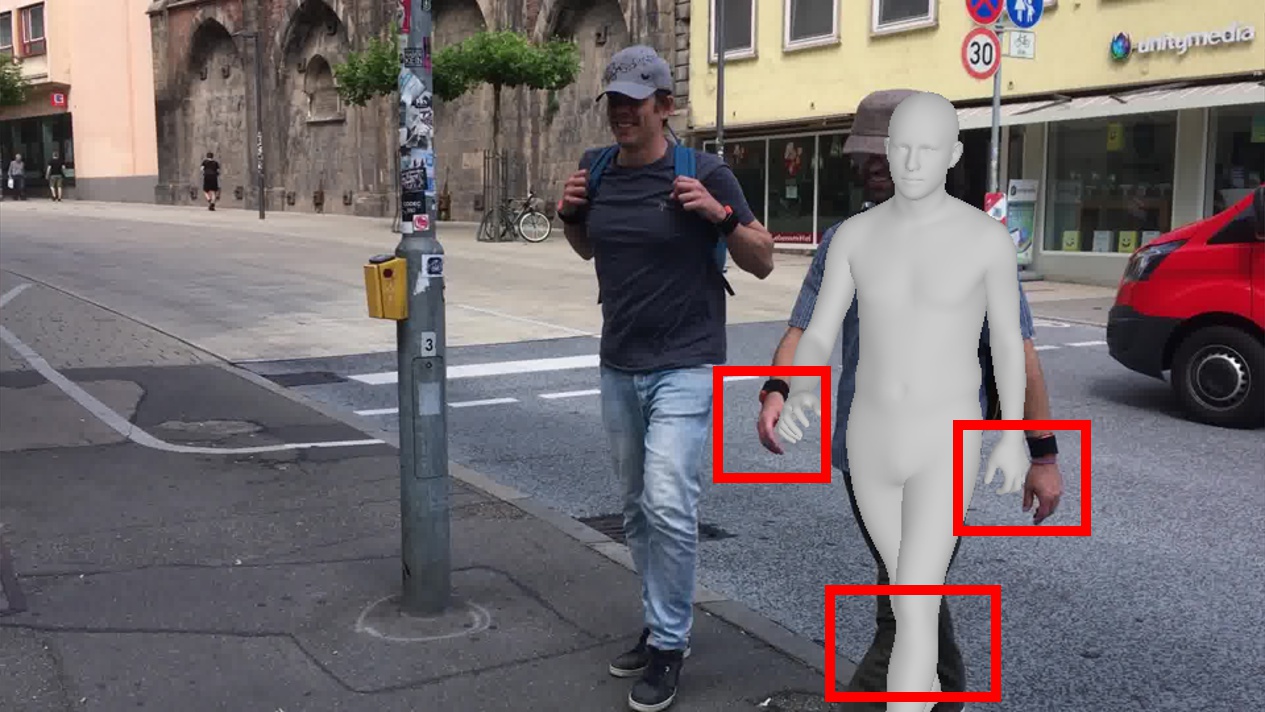
Qualitative Results
These examples show common failure modes of deterministic pipelines under ambiguity. Compared with GVHMR and GENMO, our method produces distal poses that better match the visible evidence.









Runtime Analysis
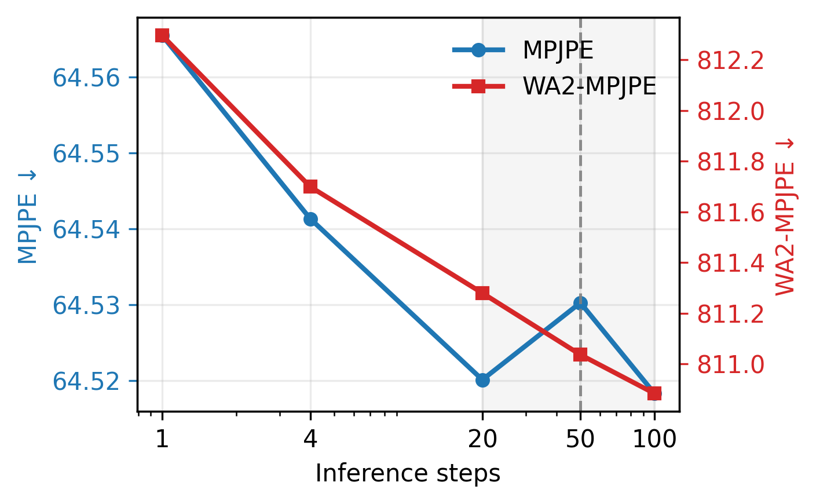
On a 1193-frame sequence, the full two-stage model requires 3.92 ± 0.03 seconds versus 0.41 ± 0.01 seconds for GVHMR and uses 1057.0 MB versus 303.6 MB of peak GPU memory on an RTX A5000. With 50 denoising steps, it still runs at 304.45 FPS, and the cost can be reduced with fewer steps.
Appendix Figures and Tables

Per-Joint Baseline Error Analysis
| Joint group / joint | 3DPW | EMDB-1 | RICH | Mean |
|---|---|---|---|---|
| Torso joints | ||||
| Pelvis / root | -- | 14.71 | 10.74 | 12.73 |
| Left hip | 16.97 | 9.32 | 8.37 | 11.55 |
| Right hip | 16.97 | 9.32 | 8.37 | 11.55 |
| Spine / torso | -- | 55.04 | 35.71 | 45.38 |
| Neck | 47.98 | 78.48 | 62.67 | 63.04 |
| Left shoulder | 52.20 | 76.67 | 59.89 | 62.92 |
| Right shoulder | 48.17 | 75.60 | 55.66 | 59.81 |
| Non-torso joints | ||||
| Left elbow | 69.64 | 84.90 | 73.89 | 76.14 |
| Right elbow | 61.82 | 78.72 | 69.69 | 70.08 |
| Left wrist | 84.70 | 109.27 | 89.17 | 94.38 |
| Right wrist | 82.34 | 99.39 | 86.99 | 89.57 |
| Left hand | -- | 125.99 | 101.72 | 113.86 |
| Right hand | -- | 115.88 | 99.08 | 107.48 |
| Left knee | 46.53 | 55.66 | 66.98 | 56.39 |
| Right knee | 44.57 | 56.07 | 62.71 | 54.45 |
| Left ankle | 83.42 | 89.24 | 108.91 | 93.86 |
| Right ankle | 80.06 | 92.56 | 106.87 | 93.16 |
| Left foot | -- | 104.42 | 115.53 | 109.98 |
| Right foot | -- | 107.93 | 113.44 | 110.69 |
| Anchor mean | 36.46 | 43.33 | 39.7 | 39.83 |
| Distal mean | 69.14 | 93.34 | 91.25 | 84.58 |
| Distal - anchor | 32.68 | 50.01 | 51.55 | 44.75 |
Additional Qualitative Comparisons

































































Conclusion and Limitations
We presented FactorizedHMR, a video HMR framework that uses an uncertainty-aware factorization: a deterministic stage estimates a stable torso-root anchor, and a probabilistic flow-matching stage completes ambiguity-prone non-torso articulation and world motion. This design, together with geometry-aware refinement and camera-aware synthetic supervision, improves reconstruction while preserving stability. Across camera-space and world-space benchmarks, FactorizedHMR remains strong against both deterministic and generative baselines and displays clear qualitative advantages in ambiguous scenes.
The current uncertainty partition between Stage 1 and Stage 2 is fixed, which can still fail under extreme truncation or rapid camera motion: if the Stage 1 structural anchor is biased, Stage 2 may inherit that error rather than correct it. In addition, probabilistic refinement increases inference cost, which limits practical deployment. Future work could make the factorization adaptive, improve sampling efficiency, and develop ambiguity-aware benchmarks for calibrated multi-hypothesis video HMR.
Citation
If you find this work useful, please consider citing:
@article{Kwon2026FactorizedHMR,
title={FactorizedHMR: A Hybrid Framework for Video Human Mesh Recovery},
author={Patrick Kwon and Chen Chen},
journal={arXiv preprint arXiv:2605.14854},
year={2026}
}