LT3SD : Latent Trees for 3D Scene Diffusion
LT3SD : Latent Trees for 3D Scene Diffusion
Authors : Quan Meng, Lei Li, Matthias Nießner, Angela Dai (Technical University of Munich)
Most of previous models focus on object-level generation, which assumes a fixed orientation and bounded space for class of objects, and is totally not the case for 3D scenes (high resolution, unstructured geometries, diverse object arrangements, varying spatial extents)
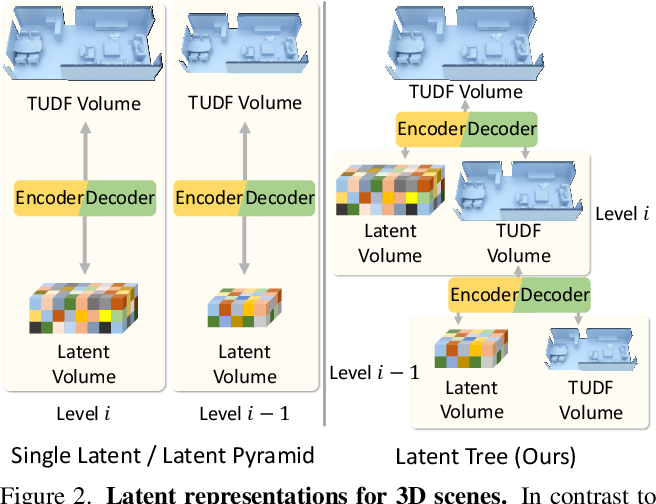
LT3SD introduces a novel latent-tree representation , a hierarchical decomposition with a series of geometry (lower freq) and latent feature (higher freq) encodings that boasts a more compact, effective representation compared to single latent codes or latent pyramid.
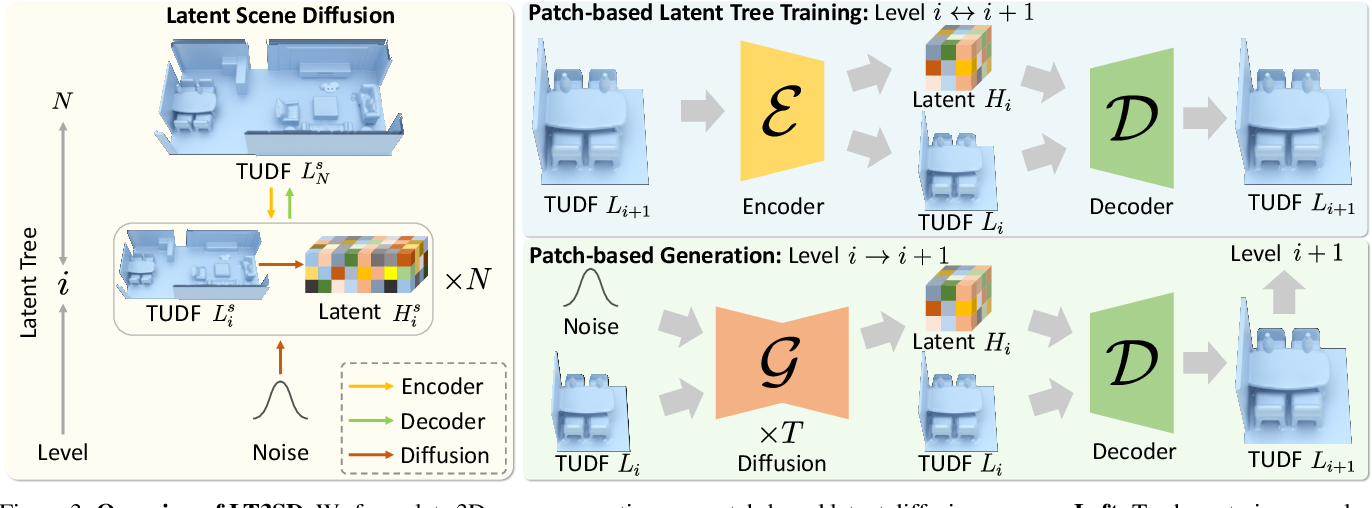
Specifically, the target ‘scene’ is represented as a truncated unsigned distance field (TUDF), which is then passed into a encoder implemented as 3D CNNs to give a low-dimensional TUDF as geometry volume, and a latent feature volume for higher frequency details. This procedure is repeated for N(=3 in the paper) steps to give a latent tree of 3 levels. For diffusion, a latent diffusion approach is used with a 3D UNet as its base. The inference structure allows a patch-by-patch scene generation (based on diffusion inpainting) and a coarse-to-fine refinement (adapting MultiDiffusion for speedup) to generate almost infinite-sized scenes.
The model was trained based on the 3D-FRONT dataset (6,479 houses), processed as UDFs with voxel size of 0.022m and random crops. The encoder/decoder training takes 5 hr ~ 1 day for single RTX A6000 GPU, and the diffusion training takes approx. 6 days for two A6000 GPUSs. Compared against PVD, NFD, and BlockFusion under various metrics, LT3SD (N=3) displayed better quantitative scores.
Citation
@misc{meng2024lt3sdlatenttrees3d,
title={LT3SD: Latent Trees for 3D Scene Diffusion},
author={Quan Meng and Lei Li and Matthias Nießner and Angela Dai},
journal={arXiv preprint arXiv:2409.08215},
year={2024}
}
Enjoy Reading This Article?
Here are some more articles you might like to read next: