SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
SynCamMaster
| Name | SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints |
|---|---|
| Authors | Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Xiao Fu, Zuozhu Liu, Haoji Hu, Pengfei Wan, Di Zhang |
| Institute | Zhejiang University, Kuaishou Technology, Tsinghua University, CUHK |
| Conference | arxiv (2412.07760) |
| Links | [ArXiV] [Project] [Code] |
| Tl;dr | 복수의 카메라 구도에 대해 똑같은 내용이 담긴 영상을 생성하는 기술 |
정리
| 무엇을 하고자 하는가 | 다중 카메라 구도에서부터의 영상 생성 | | — | — | | 왜 이전에는 해결되지 않았나 | 1. 복수의 카메라 구도에서부터의 똑같은 내용에 대한 영상 생성을, 4D 일관성을 지키면서 생성하는것
- 1을 이루기 위한, 다양한 다중 카메라 영상 데이터셋의 부재 | | 어떻게 해결하였나 | 거대 T2V 모델에 기반하며, 다양한 어댑터 모델들을 적용
-
Camera Encoder : 각 카메라들의 [R t] 입력을 인코딩 - Multi-view Synchronization Model : DiT 의 각 Transformer 레이어에 부착, 4D Consistency 를 유지한다
-
신종 데이터셋 제작 : 언리얼 엔진 기반의 다중 카메라 영상 데이터셋 + 공개되어있는 다중 이미지, 단일 영상등으로 구성
-
Hybrid Data-training 으로 훈련 최적화
기존 유사 연구
| Name | Cite | Context | | — | — | — | | SV4D | Xie et al. 2024 | * 4D 사물 제작에 특화, 고정된 카메라 각도에서만 동작 가능, 실제 영상의 환경과 괴리감이 큼
-
이미지 생성 모델의 3D prior + 비디오 생성 모델의 Motion prior Vivid-ZOO Li et al. 2024 * 4D 사물 제작에 특화, 고정된 카메라 각도에서만 동작 가능, 실제 영상의 환경과 괴리감이 큼 -
LoRA 훈련을 통해 (3D 사물 / 영상간) domain misalignment 을 해결 CVD Kuang et al. 2024 * CameraCtrl 확장, 같은 출발점에서 부터의 다양한 카메라 경로에 대해 생성 - 데이터셋 문제로 인해 좁은 범위의 카메라 경로만 가능
-
SynCamMaster는 시간축에 대한 카메라 경로 편집이 아닌, 복수의 카메라 구도에 대한 생성을 목표로 함 GCD Van Hoorick et al. 2024 * 입력 영상과 새로운 카메라 각도에 대해서 새로운 출력 영상을 생성 -
SynCamMaster 는 영상 입력이 아닌 텍스트 입력을 추구함. 해당 목표 달성 이후 Novel View 도 겸사겸사… ViewDiff Hollein et al. 2024 * 입력 이미지와 새로운 카메라 각도에 대해서 새로운 출력 이미지를 생성 (유사 시도들과는 다르게, 배경이 가능) -
영상 단위나 전경 레벨에선 문제가 여전함
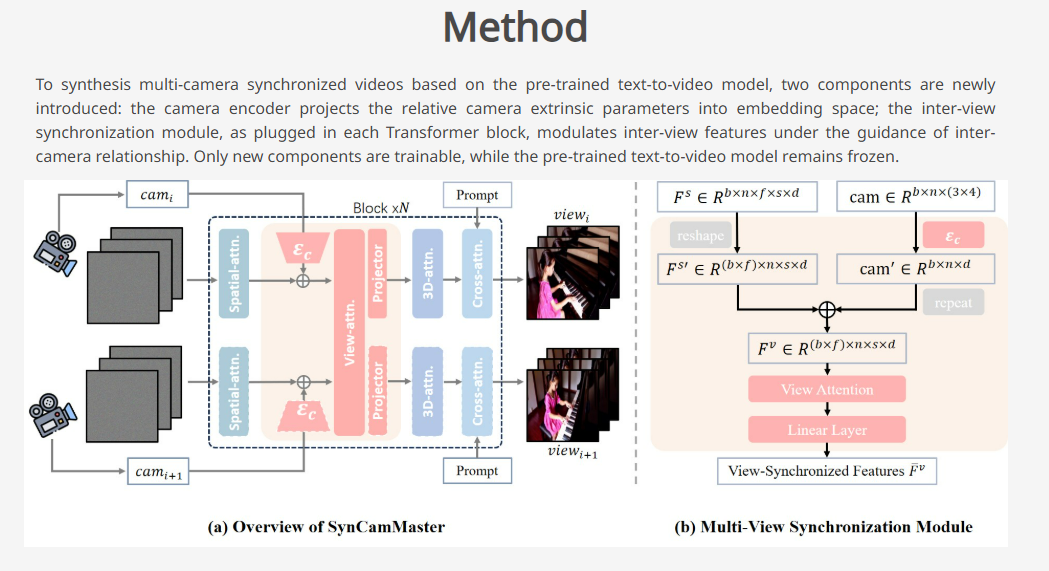
방법론 : Multi-View Synchronization Module
DiT 기반 T2V 모델 (주로 CogVideoX) 의 생성 능력을 그대로 살리면서, 복수의 카메라 구도에 대해서 동시에 생성할 수 있게 해주는 어뎁터 모듈을 각 DiT 블록마다 붙인다.
입력 : (n : 구도 수, f : 프레임 수, s : 프레임 크기 (w * h))
- 원 입력 Spatial Feature F_s (n * f * s * d)
- Camera Params cam (n * 12)
- n 개의 카메라 각도중 하나를 global 로 잡고 나머지 normalize 함
- (p.18 에선 extrinsic 과 plucker embedding 를 사용하는것의 차이에 대해 다루었는데, 큰 차이가 없었다고 결론지었음)
출력 :
- 다중 카메라 구도에 최적화된 Spatial Feature F^\bar{v}
방법론: (구도 i 에 대해서 실행)
- 카메라 인코더
- FC 레이어 (12 채널 —> d 채널) (zero. init)
- Camera Param 을 d 채널로 바꾸고, (* s) 만큼 repeat
- 이후 F_s 에 element-wise addition
- Cross-view Self Attention Layer
- 모든 구도에서의 Feature 를 다 같이 참고한다
- 원 모델의 Temporal Attention 레이어 weight 로 init
- 이후 projection (Linear+ReLU) (zero init) 를 해서 더한다
방법론 : Training Dataset & Training Strategy
총 3종류의 데이터로 구성됨
- 언리얼 엔진으로 자체 구축된 Multi View Video 데이터
- 500개의 3D 배경, 70개의 3D 에셋 (사람, 동물 등) 중에 1~2개 선택 후 애니메이션
- 각 배경당 36개의 카메라, 100개의 프레임 렌더링
- (중앙 기준 3.5~9m, elevation 0~45 에서 랜덤 샘플링)
- 훈련에서 60%의 확률로 사용
- Single View Video 에서 뽁은 Multi View Image 데이터
- RealEstate-10K, DL3DV-10K 는 카메라 경로 정보가 있는 비디오로 구성됨
- 영상에서 프레임들 샘플링해서 사용
- (프레임간 차이가 100을 넘지 않도록 해서 겹치는 구역이 있도록 함)
- 훈련에서 20%의 확률로 사용
- Generalization 에 크게 기여
- Single View Video (High Quality, 온라인에서 모음) (카메라 정보 없음)
- Regularization 으로 사용
- SynCam 은 고정된 카메라 구도를 상정했기 때문에 카메라 움직임이 크거나 static 한 영상은 배제해야 함
- downsampling 된 영상의 첫 프레임에 SAM 을 통해 객체별 seg.mask 확보
- CoTracker 를 통해 비디오 내에서 seg.mask 들의 움직임을 계산
- 특정 threshold 미만의 영상들 모두 배제
- 최종적으로 12,000개 영상 선별
- 훈련에서 20% 확률로 사용
훈련시, 처음에는 카메라 구도간 차이가 적은 세팅으로 시작해서 점진적으로 크게 가도록
- 첫 10k : 0 ~ 60도, 10~20k : 30 ~ 90도, 20k~ : 60 ~ 120도
총 50K 훈련, 해상도 (384 * 672), learning rate 1e-4, batch size 32
방법론 : Novel View Video Synthesis
원 세팅 : 입력 텍스트 + 복수의 카메라 구도
새로운 세팅 : 입력 텍스트 + 입력 비디오 + 복수의 카메라 구도
훈련시, 90% 확률로 첫번째 카메라 구도의 latent 를 입력 비디오의 latent로 교체
이후 IP2P 처럼 비디오에 대한 cfg 를 계산해서 적용 (텍스트 : 7.5, 비디오 : 1.8)
느낀점
- Data Collection 과정이 중요, 어떤 데이터를 어떻게 사용하는지로 논문의 평가가 달라질거라 생각됨
- 거대 비디오 모델 위에 올라타는 형태의 논문은 모델 구성에 한계가 있다고 생각되는데, 그럼 어떤 과정을 거쳐야 독창적인 연구를 제시할 수 있을까?
Citation
@misc{bai2024syncammaster,
title={SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints},
author={Jianhong Bai and Menghan Xia and Xintao Wang and Ziyang Yuan and Xiao Fu and Zuozhu Liu and Haoji Hu and Pengfei Wan and Di Zhang},
year={2024},
eprint={2412.07760},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.07760},
}
Enjoy Reading This Article?
Here are some more articles you might like to read next: